Bottom Line Up Front
What
I have a client that generates requests to a server. The server responds with a list of URLs. The client then requests each of the returned URLs.
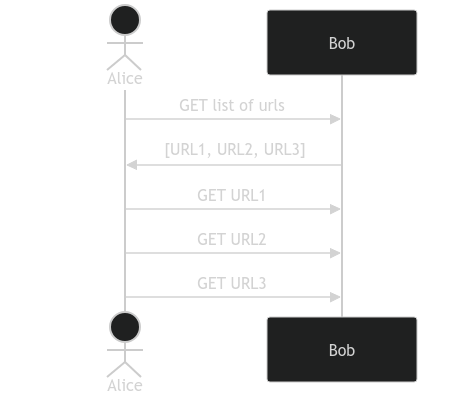
The server can return a list of URLs that point to a different server.
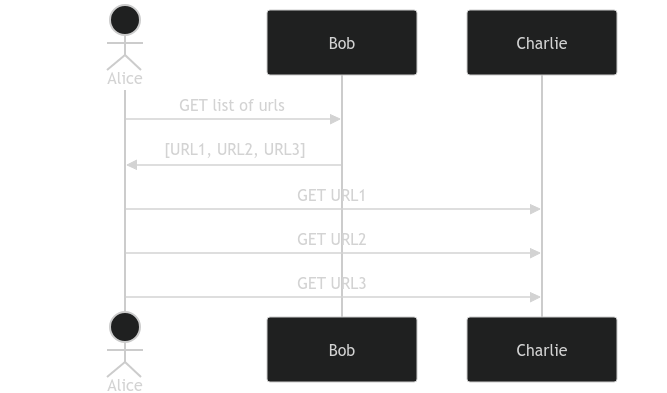
I want to migrate a subset of the the URL lists (indexes) and a subset of the URLs (files) to a separate host (Dan, I guess), so I can replay some important request/response sequences and messure their performance.
Bob and Charlie host thousands or millions of indexes and files, so I don’t want to migrate all of them, only the ones I need for the sequences I want to benchmark.
I built a YAML-configured man-in-the-middle logging and mutating HTTP proxy in Go to capture all the URL that would be requested during my benchmarks. I called it snoopy.
What?
The proxy is configured with a simple YAML file.
PyPI fits the pattern of the system I want to benchmark. It returns indexes from pypi.org that point to files on files.pythonhosted.org. If I want to log all the HTTP calls made during a call to pip add, I can’t just capture all the calls going to pypi.org because then I’d miss the equally important calls to files.pythonhosted.org.
Here’s a useful snoopy config.yaml for PyPI.
- upstream: https://pypi.org
local: 127.0.0.1:9999
logfile: pypi-index.urls
headers:
- name: User-Agent
value: snoopy/v1
response-rewrites:
- old: https://files.pythonhosted.org
new: http://localhost:9998
- upstream: https://files.pythonhosted.org
local: 127.0.0.1:9998
logfile: pypi-files.urls
This example sets up two HTTP servers. One listens on port 9999, proxies requests to pypi.org with an added User-Agent header, logs the requests to pypi-index.urls, and mutates the responses to replace occurrences of https://files.pythonhosted.org with http://localhost:9998.
The other server listens on port 9998, proxies requests to https://files.pythonhosted.org, and logs all requests to pypi-files.urls.
Logging and Mutating
With the above config, I can start the server in one terminal window:
% make run
golangci-lint run
go test -race -cover ./...
? mp/snoopy/cmd/snoopy [no test files]
? mp/snoopy/pkg/logging [no test files]
ok mp/snoopy/pkg/snoopy (cached) coverage: 60.0% of statements
CGO_ENABLED=0 go build -o . ./cmd/...
LOG_LEVEL=debug ./snoopy
time=2024-01-10T21:13:08.827-08:00 level=DEBUG source=pkg/snoopy/snoopy.go:51 msg="Starting snoop server" local=127.0.0.1:9998 upstream=https://files.pythonhosted.org local=127.0.0.1:9998 upstream=https://files.pythonhosted.org logfile=pypi-files.urls
time=2024-01-10T21:13:08.827-08:00 level=DEBUG source=pkg/snoopy/snoopy.go:51 msg="Starting snoop server" local=127.0.0.1:9999 upstream=https://pypi.org local=127.0.0.1:9999 upstream=https://pypi.org logfile=pypi-index.urls
Then run a pip install in a different window, pointing it at snoopy.
% pip install --trusted-host localhost --index-url http://localhost:9999/simple --no-deps pandas
snoopy rewrote the pypi.org response’s references to https://files.pythonhosted.org as http://localhost:9998, and generated two log files.
% cat pypi-index.urls
https://pypi.org/simple/pandas/
% cat pypi-files.urls
https://files.pythonhosted.org/packages/54/be/98b894bef9acfc310de70fc03524473a9695981e1e87c7afa56ada08f016/pandas-2.1.4-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.metadata
https://files.pythonhosted.org/packages/54/be/98b894bef9acfc310de70fc03524473a9695981e1e87c7afa56ada08f016/pandas-2.1.4-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
Now we have a list of all the HTTP requests we’d need to serve from an arbitrary server to successfully pip install --no-deps pandas. To populate such a server, we can concatenate the files and insert a curl -O in front of each line, then run it as a shell script.
snoopy can also insert cookies and HTTP headers, which can be very useful if some of the proxied endpoints require particular cookies or headers - for example, API keys.
Did it work?
Yes, it worked. I got the information I needed to set up my test.
Why, though?
Why not use someone else’s code? I wrote snoopy on the weekend when I was supposed to be folding laundry or something. Isn’t that reason enough?
I took the opportunity to practice some fundamentals, like parsing YAML, serving and requesting HTTP, and unit testing with httptest.Server. I gained insights into the system I was testing that may not have been surfaced by using somoene else’s tooling.
Mostly, though: I find programming fun. Sure, learning someone else’s version of the same thing has benefits, but it’s just not as fun as writing my own code.
YMMV.
Parting Praise
My initial implementation supported just one HTTP listener, but when I realized I needed 2+, my code changes were easy and elegant, because Go concurrency is easy and elegant.
var snoop Snoop
err = yaml.NewDecoder(file).Decode(&snoops)
became
var snoops []Snoop
err = yaml.NewDecoder(file).Decode(&snoops)
and
func (s *Snoopy) Run() {
snoop := s.snoop
snoop.Logger.Debug("Starting snoop server", "local", snoop.Local, "upstream", snoop.Upstream, "logfile", snoop.Logfile)
if err := http.ListenAndServe(snoop.Local, &snoop); err != nil {
snoop.Logger.Error("ListenAndServe:", err)
panic(err)
}
}
became
func (s *Snoopy) Run() {
var wg sync.WaitGroup
for _, snoop := range s.snoops {
snoop := snoop
wg.Add(1)
go func() {
defer wg.Done()
snoop.Logger.Debug("Starting snoop server", "local", snoop.Local, "upstream", snoop.Upstream, "logfile", snoop.Logfile)
if err := http.ListenAndServe(snoop.Local, &snoop); err != nil {
snoop.Logger.Error("ListenAndServe:", err)
panic(err)
}
}()
}
wg.Wait()
}
The new Run() is longer, but only because of standard-issue boilerplate familiar to most Gophers.